[30.09.2009] Can be the FidoBase Project be part of the Fido-History-Project ?
Well, because the FidoBase contains messages from at least 1996 its also be a part of the Fido-History-Project.
The only problem is, its not yet well documented.
Starting today, i'll try some documentation on this. (Uli)
- Table of contents
- Chapter 1 - Intro
- Chapter 2 - Analyze, Discussion
- Chapter 3 - Practicle Starters for Deployment
- Chapter 4 - Intermediate Summary
Chapter 1 - Intro
1.1 Project Overview
Project Team Members:
- Dirk Astrath
- Kees van Eeten
- Uli Schroeter
Project Development starts:
... some years ago (2004?, 2005?, 2006?) around Pfingsten
Data Source:
based on main rescans from Olav, Knut and Dirk (and some others), all *.pkt
Program Souce:
Actual Source is a bundle of PERL scripts.
Port to PHP is probably possible
FidoBase actual State (1.10.2009):
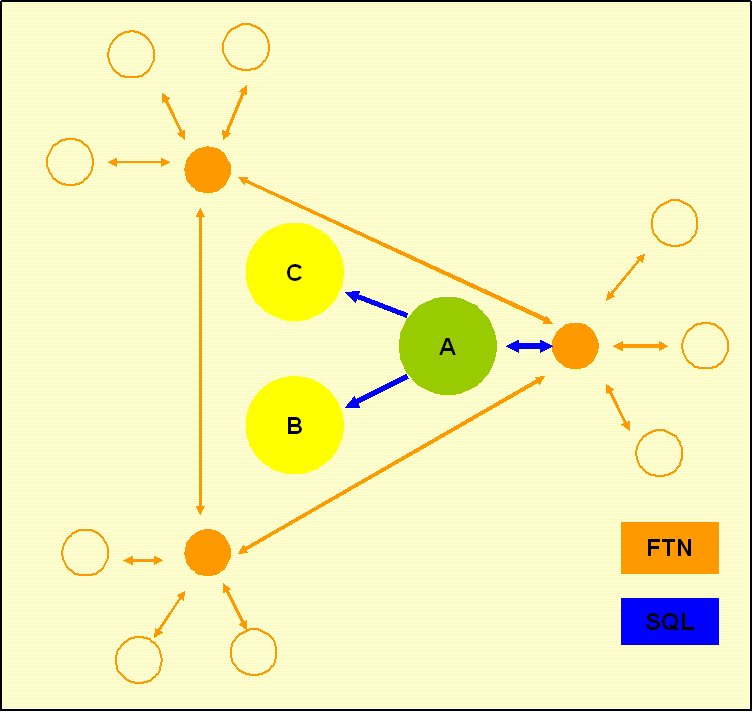
The actual state is:
- only Cluster Node A imports mails from the ftn network into the MySQL db and then pushes by sql mails to the other cluster nodes
- There is no import or export activity on clusternodes B and C as of missing scripts
- Each of the cluster nodes systems has several downlinks thru ftn connections
Example: if downlink #2 at ftn node B writes a mail, the mail flows thru ftn node B to ftn node A, pushed with a perl script into the MySQL database of cluster node A and then will be forwared to cluster node B with sql inserts (also to cluster node C).
The actual system uses the Dual Write method.
Pro's: its easy to implement
Con's: if one node hangs, the replications hangs
Better:
Using an async multiple nodes replication mode
Database Structure
- 37 tables named echo_#, where # = 0..9, a..z and temp
- Each table contains mails from all the echos starting the named first letter
- Each record of each mail contains the area name in field folder
- Structure of each table is identical
- echo_temp includes the actual mails as duplicate upto 10 days (not yet working)
| fieldname | data type | not NULL | autoinc | flags | default value |
|---|---|---|---|---|---|
| id | INTEGER | No Unsigned, no ZeroFill | NULL | ||
| ftscdate | VARCHAR(20) | No Binary | |||
| datetime | TIMESTAMP | CURRENT_TIME | |||
| folder | VARCHAR(72) | No Binary | |||
| fromnode | VARCHAR(72) | No Binary | |||
| tonode | VARCHAR(72) | No Binary | |||
| fromname | VARCHAR(36) | No Binary | |||
| toname | VARCHAR(36) | No Binary | |||
| subject | VARCHAR(72) | No Binary | |||
| attrib | SMALLINT(5) | Unsigned, No ZeroFill | 0 | ||
| msgid | VARCHAR(72) | No Binary | |||
| replyid | VARCHAR(72) | No Binary | |||
| origin | VARCHAR(72) | No Binary | |||
| path | VARCHAR(255) | No Binary | |||
| local | CHAR(1) | Not Binary, Not ASCII, Not UNIC | Y | ||
| rcvd | CHAR(1) | Not Binary, Not ASCII, Not UNIC | N | ||
| sent | CHAR(1) | Not Binary, Not ASCII, Not UNIC | N | ||
| kludges | MEDIUMBLOB | NULL | |||
| body | MEDIUMBLOB | NULL | |||
| seenby | MEDIUMBLOB | NULL | |||
| datewritten | DATETIME | NULL | |||
| Uplink | INT(10) | Unsigned, Not ZeroFill | 0 |
CREATE TABLE `echo_0` ( `id` int(11) NOT NULL auto_increment, `ftscdate` varchar(20) NOT NULL default '', `datetime` timestamp NOT NULL default CURRENT_TIMESTAMP on update CURRENT_TIMESTAMP, `folder` varchar(72) NOT NULL default '', `fromnode` varchar(72) NOT NULL default '', `tonode` varchar(72) NOT NULL default '', `fromname` varchar(36) NOT NULL default '', `toname` varchar(36) NOT NULL default '', `subject` varchar(72) NOT NULL default '', `attrib` smallint(5) unsigned NOT NULL default '0', `msgid` varchar(72) NOT NULL default '', `replyid` varchar(72) NOT NULL default '', `origin` varchar(72) NOT NULL default '', `path` varchar(255) NOT NULL default '', `local` char(1) NOT NULL default 'Y', `rcvd` char(1) NOT NULL default 'N', `sent` char(1) NOT NULL default 'N', `kludges` mediumblob, `body` mediumblob, `seenby` mediumblob, `datewritten` datetime default NULL, `Uplink` int(10) unsigned default '0', PRIMARY KEY (`id`), UNIQUE KEY `dupecheck` (`folder`,`ftscdate`,`msgid`,`subject`), KEY `Export` (`datetime`,`folder`) ) ENGINE=MyISAM DEFAULT CHARSET=latin1;
1.3 ToDo / Wishlist
- PHP Import / Export Scripts
- Connect downlinks to all nodes (same sessionpwd database)
- Sync to all nodes not only triggered by one node
- Authoritive recovery on disaster recovery
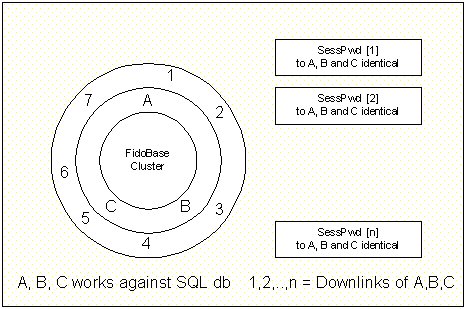
Each downlink can connect to all cluster nodes. The connection will be a ftn mailer session. The session password is read from the online database that resides on each nodes cluster site. Mailbundles will be streamed online, on the fly to the connected downlink from the nodes cluster database (echo_temp).
If the downlink connects a 2nd time onto anothers cluster node, the tables needs updated just in time, so the downlink doesn't receive the mailbundle again.
So the actual system needs two more tables:
- Password Table
- Actual Downlinks state
| Table: DLSTAT | |||||
|---|---|---|---|---|---|
| Downlink 1 | Downlink 2 | Downlink 3 | ... | Downlink n | |
| Echo 1 | HWM.1.1 | -.- | -.- | ... | HWM.n.1 |
| Echo 2 | HWM.1.2 | HWM.2.2 | HWM.3.2 | ... | -.- |
| Echo 3 | -.- | -.- | HWM.3.3 | ... | HWM.n.3 |
| ... | |||||
| Echo n | -.- | HWM.2.n | -.- | ... | -.- |
normalized
| Table: DLSTAT | ||
|---|---|---|
| Link | Link Stat | |
| Echo 1 | LinkID 1 | HWM.1.1 |
| Echo 2 | LinkID 1 | HWM.1.2 |
| Echo 2 | LinkID 2 | HWM.2.2 |
| Echo 2 | LinkID 3 | HWM.3.2 |
| Echo 3 | LinkID 3 | HWM.3.3 |
| Echo 3 | LinkID n | HWM.n.3 |
| Echo n | LinkID 2 | HWM.2.n |
| Table: SESSPWD | |||
|---|---|---|---|
| Link ID | (Default Link) | AKA | PWD |
| LinkID 1 | Link 1 | Aka 1 | Pwd 1 |
| LinkID 2 | Link 2 | Aka 2 | Pwd 2 |
| LinkID 3 | Link 3 | Aka 3 | Pwd 3 |
| LinkID n | Link n | Aka n | Pwd n |
1.4 Database Sync Methods
- Dual Writes1
- Coordinated Commits
- Others?
1.4.1 Dual Writes
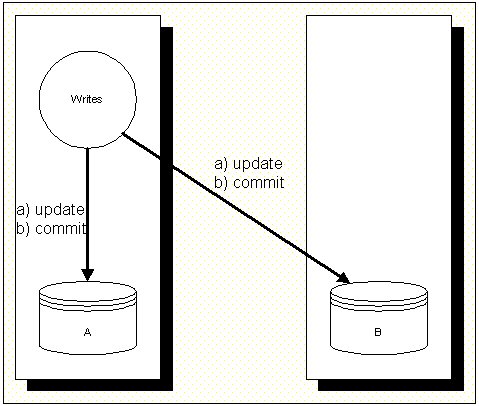
1 Dual Writes
This method is actual used by the FidoBase project (see above).
1.4.2 Coordinated Commits
Chapter 2 - Analyze, Discussion
2.1 Using Queues?
- Based on the Dual Writes method, each Commit is queued for all connected nodes.
- If a node is offline, the queue increases until the node is back online.
- Each node has to use a detect and resolve conflicts resolution algorhytm (dupe detection).
- If a dupe is identified, the related records needs to be bounced.
- Each node has two inputs: the ftn mailer input and the syncing queue.
- Both queues needs to be merged at each nodes cluster end.
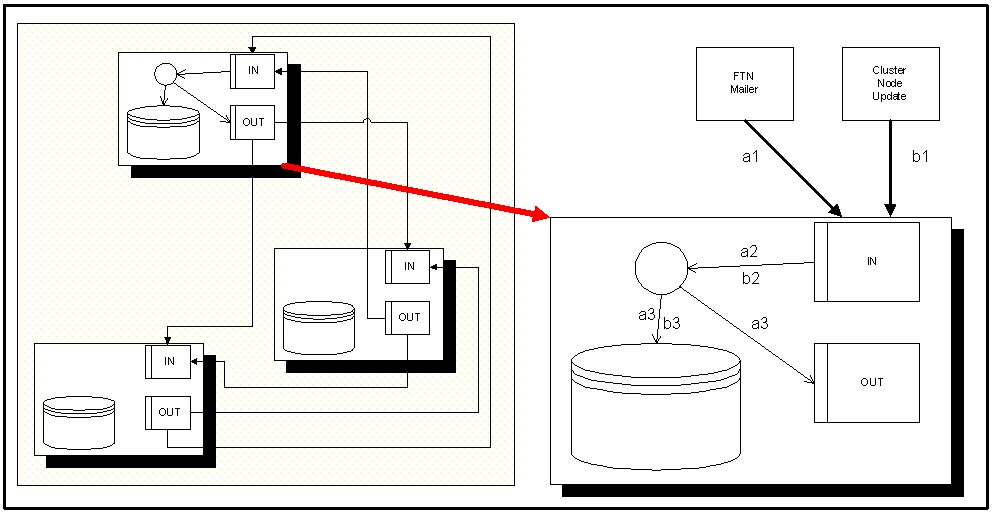
Queued Writes
Queue-IN: needs information of source (FTN Mailer or Cluster Node Update).
-
Processing needs information about source of update, so updates from FTN mailers needs to be written to database and Queue-OUT.
Flow: a1 -> IN -> a2 -> Replication Agent -> pushes a3 to Database and pushes a3 to Queue-OUT -
Udpates from Cluster nodes needs to be written only to database.
Flow: b1 -> IN -> b2 -> Replication Agent -> pushes b3 to Database only
2.2 Push or Pull Updates or Both?
Push Update
- On Push updates the push fails if a cluster node is offline
- Leave update if cluster node is offline
- The Push update can be done if the offline cluster is online next time
Pull Update
- On Pull updates the initiating cluster node doesn't need check each time a cluster node goes offline
- Updates are as long in the queue as long as a cluster node is offline
Push and Pull Update
- Possible conflicting Push and Pull update if an offline cluster node comes online the next time
- Updates are as long in the queue as long as a cluster node is offline
- Alternate: Push update on initiating first write. If this fails, still leave the record in the queue and wait for a Pull update2
Push and/or Pull or Both updates needs info about available cluster nodes.
... so the list of cluster nodes can increase / decrease and is flexible.
If a cluster node goes offline forever, all related records in the Queue-OUT can be deleted.
Problem solved.
Records needs to be created in the Queue-OUT for all cluster nodes except the own cluster-node.
2.3 List of Processes
2.3.1 Process 1 - FTN mailer connection
- This process writes updates to the Queue-IN with the information of source (FTN mailer or Cluster node update).
- Triggers the Update Process (2)
2.3.2 Process 2 - Update Process
- The Update Process is the main sync process on each cluster node.
-
This process has to ...
- checks for updates in the Queue-OUT of all other cluster nodes x2) (Pull replication) (transfer from Queue-OUT of other cluster nodes to the own Queue-IN)
- check for updates in the Queue-IN
- check for dupes (conflict detection and resolution)
- pushes writes to the database
- pushes writes to the Queue-OUT (Push replication)
- pushes initial writes (one time only) to the Queue-IN of all other cluster nodes (Push replication)
- This process needs to be triggered by the FTN mailer process and on recuring schedules.
2.3.3 Process 3 - Maintenance Process
If a cluster node goes offline forever, the queues still needs cleaned from records for this offline cluster node.
2.4 Full and/or partial Rescans
(between cluster nodes)
Full or partial rescans are no problem with this design. Trigger a full rescan exports all records from the database to the Queue-OUT for a specific cluster node.
Partial rescans can be handled by count or days (export the last 5000 records, export the last 3 months). As of the dupe detection on the other side, dupe records are prevented.
2.5 Downlinks Handling?
This procedure describes only the sync of cluster nodes with updates from FTN mailers. But it doesn't includes the update to the downlinks.
How get the downlinks their bundles?
- i. Handle downlinks as they were cluster nodes too ?
- ii. Handle downlinks with tables of highwatermarks for each connected area ?
i. has the problem, that each cluster node has to queue all the mails for all downlinks, so the mails in the Queue-OUT needs to be duplicated to all real cluster nodes, because each downlink can connect to one of the other real cluster nodes.
If the downlink connects to one real cluster node, the pulled mails from Queue-OUT also needs deleted from the Queue-OUT of the other real cluster nodes too.
ii. the order of mails in each cluster nodes database can vary as the input may be unordered. This complicates the use of highwater marks. The highwater mark in database of cluster node A isn't the same highwater mark in the 2nd database of cluster node B and vice versa. If a downlink connects to a cluster node, the cluster node has to identify the point of which mails the downlink has received the last mail in one area (this is the same problem for all connected areas).
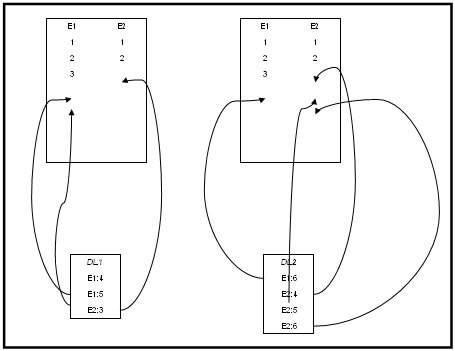
Downlink 1 connects to Cluster Node A, transfers some mails
Downlink 2 connects to Cluster Node B, transfers some mails
Mails from Downlink 1 still gets replicated from Cluster Node A to Cluster Node B
and Mails from Downlink 2 still gets replicated from Cluster Node B to Cluster Node A
All tables are synchronized
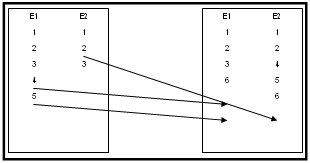
What's next time Downlink 2 connects to Cluster Node A and tries to get his 'actual' mails?
Remember: Downlink 2 sends mails Echo 1: #6, Echo 2: #4, #5, #6.
The last sent mails for Echo #1 is #3, and for Echo 2 is #2.
So sending all mails after Echo 1 #3 and Echo 2 #2 doesn't fit.
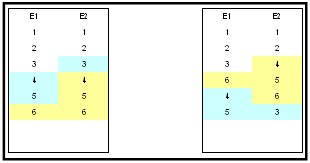
Downlink 2 only needs the blue ones.
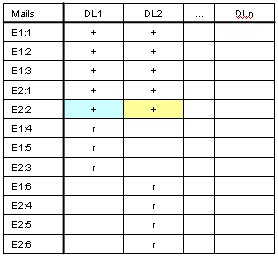
Filling Temp Downlinks table
Using addtl. Temp table?
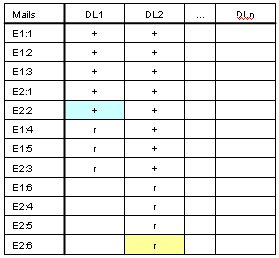
Temp table updated at Cluster Node A for Downlink 2
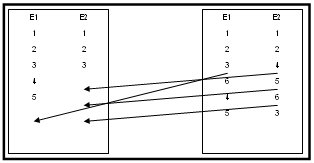
The next time, Downlink 2 connects to Cluster Node A, Cluster Node A sends mail beginning after row E2:2 =>
E1:4, E1:5, E2:3, skipping: E1:6, E2:4, E2:5, E2:6
and sets Highwate mark to row E2:6
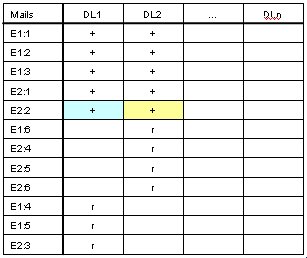
Temp table on Cluster Node B
Replicate information to Cluster Node B:
DL2: E1:4+, E1:5+, E2:3+
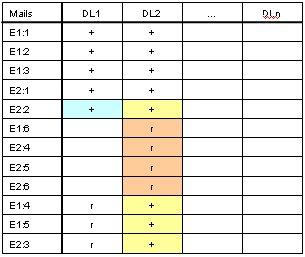
Temp table updated on Cluster Node B
now receiving update information from Cluster Node A
New state Temp table on Cluster Node B
Flat table structure for Temp Downlinks table
[-----------Mails-----------] [DL1,DL2,...,DLn] Table (?), Folder (?), MailID, DownlinkID, State
Replication Agent Procedure:
for i = 1 to n-Updates
for j = 1 to n-Downlinks
Dest = Downlinks[j]
if Dest != MyNodeID
case Action==AddMail
Queue-OUT(From:MyNodeID,To:Dest,Action:AddMail,Content:add(id,ftscdate,datetime,folder,...))
case Action==UpdateTemp
Queue-OUT(From:MyNodeID,To:Dest,Action:UpdateTemp,Content:update(MailID,DL#,state))
endif
next
next
2.6 Requirements
- Mails need unique IDs (not index autoincrement!) so entries can be identified accross all cluster node tables (requirement results from temp downlinks table, see above i.e. E2:3)
-
Replication needs some informations:
- Replication source (FTN mailer, Cluster node)
- Replication target (Cluster node A, B, ...)
- Action requiered: add new mail, update temp downlinks table
- Action on Table Name (?): TableName
-
Replication records uses different record structures (echoes tables, temp downlinks table)
{Echoes Table: id, ftscdate, datetime, folder, fromnode, ...}
{Temp Table: MailID, DL#, state (+|r|?)}
2.7 Further Actions
2.7.1 Add, Remove Cluster Nodes
To add and remove Cluster Nodes, a table that holds the Cluster Nodes info needs to exist.
Update Record thru Replication process.
Proposed table structure Cluster Nodes:
ClusterNodesID, AKA, Name
2.7.2 Add, Remove Downlinks
To add and remove Downlinks, a table for Downlinks (with Session Password) needs to exist.
Update record thru Replication process.
Proposed table structure Cluster Nodes:
DownlinkID, AKA, Name, SessionPwd
2.7.3 Update Table Structures?
To add and remove Table Columns (Structureupdate) a procedure needs to exist
Update table structures thru Replication process ?
2.7.4 Updated Replication Agent Procedure
for i = 1 to n-Updates
for j = 1 to n-ClusterNodes
Dest = ClusterNodes[j]
if Dest != MyNodeID
case Action==AddMail
Queue-OUT(From:MyNodeID,To:Dest,Action:AddMail,Content:add(id,ftscdate,datetime,folder,...))
case Action==UpdateTemp
Queue-OUT(From:MyNodeID,To:Dest,Action:UpdateTemp,Content:update(MailID,DL#,state))
case Action==AddClusterNode
Queue-OUT(From:MyNodeID,To:Dest,Action:AddClusterNode,Content:add(ClusterNodeID,AKA,Name))
case Action==AddDownlink
Queue-OUT(From:MyNodeID,To:Dest,Action:AddDownlink,Content:add(DownlinkID,AKA,Name,SessionPwd))
case Action==DelClusterNode
Queue-OUT(From:MyNodeID,To:Dest,Action:DelClusterNode,Content:del(ClusterNodeID))
case Action==DelDownlink
Queue-OUT(From:MyNodeID,To:Dest,Action:DelDownlink,Content:del(DownlinkID))
endif
next
next
2.8 Exports, External Links and Dupe Ring detections
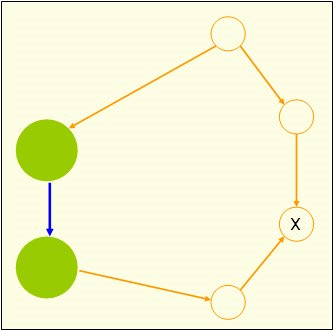
Dupe Detection with external links
Case:
Two links connected to one of the cluster nodes (aka BBR0)
One link sends new mail (FTN mailer goes to Queue-IN)
MsgID#1 created at cluster node A
Another link sends the same mail to another cluster node (FTN mailer)
MsgID#2 created on cluster node B
Now dupe collision detection needs to compare MsgID #1 and #2
Which MsgID will win ?
Using the cluster node table ascending order of hirarchy can be used to for select the higher priority for one of these mails
If one cluster node goes offline, the next one is the virtual master for the moment of dupe collision
If the failed cluster node comes back online, the authoritive restore overwrites dupe collisions upto the moment the cluster node is in sync again.
Next problem:
One link rcvd mail from downlink 1, downlink sends also mail thru FTN channel to downlink 2 (but needs some time). Cluster node forwards and exports mail to downlink 2. Now dupe detection is at FTN channel side, unreachable for the cluster node dupe detection process.
Prevent sending mails to downlinks with known addtl. FTN links ?
Implement a path analyse ? (aka CPD circular path detection)
The collision detection process:
- rcvd dupe msg
- is one of the msgs from (last) dupe-master?
- if yes, replace Id with Id from dupe-master
- if no, is (last) master online?
- send msgs request to master
- dupe-master sends replace Id with dupe-master-Id for msg#
- if dupe-master isn't online, the next one in the cluster nodes table becomes dupe-master
The problem:
FTN mailer downlinks doesn't have their own intelligence but needs to be included into the sync schema. One possible solution can be to build up the replication schema for FTN mailer downlinks within the database virtualy. This needs inclusion for all connected and sub-connected FTN mailer systems that are connected to any of the echo areas. If mails are exported to FTN mailer downlink #1 who has 2 FTN mailer downlinks the export has to be recorded into the system too.
Cluster node A exports to FTN mailer downlink #1.
Tables needs updated for downlink #1.
Downlink #1 has also 2 more downlinks, downlink #2 and #3.
Tables for downlinks #2 and #3 has to be added into the system and needs to be updated in the same way as downlink #1 table is updated.
By default actions, larger dupe ring detection is impossible as the database actions are as fast as possible. Mail flow thru the FTN mailers are someway delayed.
Proposed large dupe ring detection:
Sending Test pings, that aren't included into the database ? and delayed upto the receiving from another FTN mailer ? (delayed database transfer actions on mails on continous schedules?)
If sometimes the cluster node insert into database process of a single mail will be delayed, the mailflow thru the FTN mailer ring starts and ends up on the same cluster node or another cluster node, the information of the dupe ring can be detected.
Using this mechanism, is an option in detecting dupe rings and further prevention of dupes by setting the related FTN mailer downlink to import or export state only.
But the problem on this idea is, the mails that are used as test ping needs to be production mails to be tossed into the mail databases of all FTN downlinks to get them passed thru. ;& so that sending test ping mails have to use production mails ... i.e. monthly rules posting ?!?
Sending test pings in the cluster node synchronisation is no problem, but sending test pings thru FTN downlinks tossers, that aren't aware of special 'test ping' mails is a problem.
Solution search:
Adding a X-TEST kludge to such a mail? (added X-TEST: 002002440112000000091009113800 to one mail)
If a rules posting is received at one cluster node, the rules posting will be added the delayed action - meaning, waiting 24 hours to send out to the next downlink, awaiting next receive, send to the next downlink, wait again 24 hours and so on upto the last downlink (adding different X-TEST kludges to different downlinks? to identify late distributions thru other channels?!?).
If once a mail with an X-TEST is received by a cluster node, this X-TEST kludge can be identified to a special test mail sent to downlink 1, received from downlink 2, so between downlink 1 and downlink 2 exists a dupe ring and the path can be read from the mail received from downlink 2 ....
Area info will be great, added to the X-TEST kludge ... so it has to read (field-length):
X-TEST: [area(1-n)]-[zone(3)][net(5)][node(5)][point(5)][year(2)][month(2)][day(2)][hour(2)][minute(2)][seconds(2)][[optional random number]]
sample:
X-TEST: fidocon.bleichenbach.1996-002002440112000000091009113800
to be continued ...
2.9 Path Analysis
Sample: FIDOCON.BLEICHENBACH.1996
PATHS: Maintain and report PATHS a message takes within an echo.
Copyright (C) 1991-1992, Graham J Stair. All rights reserved.
Release 2a for DOS (10th January 1993, 21:21) {-? for help}
Checked on : Wed Oct 07 18:04:20 2009
Number of nodes : 23
Number of messages : 344xx
Earliest message : Nov 27 2008
Latest message : Feb 05 2009 22:28:16 2106
2:244/1120 (6 of -31120)
+->2:244/1120.2 (784 of 784)
|
+->2:240/4030 (4983 of 4983)
|
+->2:244/1120.6 (2066 of 2066)
|
+->2:244/1117 (1371 of 1371)
|
+->2:240/2188.262 (9401 of 9401)
|
+->2:2443/1313 (0 of 5490) -------+
| +->2:280/5003 (19 of 2988) |
| | +->2:280/5003.4 (2967 of 2967) |
| | +->2:280/5555 (2 of 2) |
| | | |
| | +->2:280/5004 (0)
| | |
| +->2432/200 (0 of 168) -----+ |
| | +->2:2448/44 (0 of 167) | |
| | | +->2:2448/44.23 (167 of 167) | |
| | | V V
| | +->2:2432/390 (1 of 1) ? ?
| | | (+->2:240/2188 (0 of 9401) ???)
| | ???
| | | -------> 2:240/5832 ?
| | | -------> 2:2437/33 ?
| | SeenBy
| | +->2:24/905
| | +->2:240/2188
| | +->2:240/5778
| | +->2:244/1200
| | +->2:249/3110
| | +->2:313/41
| | +->2:423/81
| | +->2:2411/413
| | +->2:2432/0
| | +->2:2432/201
| | +->2:2432/215
| | +->2:2432/300
| | +->2:2433/401
| | +->2:2437/40
| | +->2:2443/1311
| | +->2:2452/250
| |
| |
| +->2:2443/1313.13 (1139 of 1139)
| |
| +->2:2443/1313.666 (6 of 6)
| |
| +->2:2443/1313.1168 (29 of 29)
| |
| +->1/2443 (14 of 14)
| |
| +->2:2443/1313.80 (4 of 4)
| |
| +->2:2443/1313.87 (3 of 3)
| |
| ???
|
+->2:244/1120.21 (9868 of 9868)
|
+->2:244/1120.23 (1586 of 1586)
+---------------------------------------------------------------------+
Average msg hops: 1.9 Maximum msg hops: 4
+---------------------------------------------------------------------+
Links between Dec 2009 and Apr 2010
2:244/1120 (6 of -31120)
+->2:244/1120.2 (784 of 784)
|
+->2:240/4030 (4983 of 4983)
|
+->2:244/1120.6 (2066 of 2066)
|
+->2:244/1117 (1371 of 1371)
|
+->2:240/2188.262 (9401 of 9401)
|
+->2:280/5003 (19 of 2988)
| +->2:280/5003.4 (2967 of 2967)
| +->2:280/5555 (2 of 2)
| |
| +->2:280/5004 (0)
|
+->2:244/1120.21 (9868 of 9868)
|
+->2:244/1120.23 (1586 of 1586)
:
[broken link]
:
+->2:2443/1313 (0 of 5490) -------+
: |
[broken link] |
: |
+->2432/200 (0 of 168) -----+ |
| +->2:2448/44 (0 of 167) | |
| | +->2:2448/44.23 (167 of 167) | |
| | V V
| +->2:2432/390 (1 of 1) ? ?
| | (+->2:240/2188 (0 of 9401) ???)
| ???
| | -------> 2:240/5832 ?
| | -------> 2:2437/33 ?
| SeenBy
| +->2:24/905
| +->2:240/2188
| +->2:240/5778
| +->2:244/1200
| +->2:249/3110
| +->2:313/41
| +->2:423/81
| +->2:2411/413
| +->2:2432/0
| +->2:2432/201
| +->2:2432/215
| +->2:2432/300
| +->2:2433/401
| +->2:2437/40
| +->2:2443/1311
| +->2:2452/250
|
|
+->2:2443/1313.13 (1139 of 1139)
|
+->2:2443/1313.666 (6 of 6)
|
+->2:2443/1313.1168 (29 of 29)
|
+->1/2443 (14 of 14)
|
+->2:2443/1313.80 (4 of 4)
|
+->2:2443/1313.87 (3 of 3)
|
???
+---------------------------------------------------------------------+
Update 22.4.2010
PATHS: Maintain and report PATHS a message takes within an echo.
Copyright (C) 1991-1992, Graham J Stair. All rights reserved.
Release 2a for DOS (10th January 1993, 21:21) {-? for help}
Checked on : Wed Apr 10
2:244/1120 (6 of -31120)
+->2:244/1120.2 (784 of 784)
|
+->2:240/4030 (4983 of 4983)
|
+->2:244/1120.6 (2066 of 2066)
|
+->2:244/1117 (1371 of 1371)
|
+->2:240/2188.262 (9401 of 9401)
|
+->2:280/5003 (19 of 2988)
| +->2:280/5003.4 (2967 of 2967)
| +->2:280/5003.666
| +->2:280/5555 (2 of 2)
| |
| +->2:280/5004 (0)
|
+->2:2448/44 (0 of 167)
| +->2:2448/44.23 (167 of 167)
|
+->2:244/1120.21 (9868 of 9868)
|
+->2:244/1120.23 (1586 of 1586)
|
+->2:244/1200
| |
| +->2:2432/200 (0 of 168)
| |
| +->2:2432/390 (1 of 1)
| |
| ???
| |
| |
| SeenBy
| +->2:24/905
| +->2:240/2188
| +->2:240/5778
| +->2:249/3110
| +->2:313/41
| +->2:423/81
| +->2:2411/413
| +->2:2432/0
| +->2:2432/201
| +->2:2432/215
| +->2:2432/300
| +->2:2433/401
| +->2:2437/40
| +->2:2443/1311
| +->2:2452/250
|
:
[broken link]
:
+->2:2443/1313 (0 of 5490) -------+
: (+->2:240/2188 (0 of 9401) ???)
[broken link]
| -------> 2:240/5832 ?
| -------> 2:2437/33 ?
+->2:2443/1313.13 (1139 of 1139)
|
+->2:2443/1313.666 (6 of 6)
|
+->2:2443/1313.1168 (29 of 29)
|
+->1/2443 (14 of 14)
|
+->2:2443/1313.80 (4 of 4)
|
+->2:2443/1313.87 (3 of 3)
|
???
+---------------------------------------------------------------------+
2.10 The DOS timepacking problem
As in the history plain old DOS software is used and timestamps are packed with the DOS timepack algorhytm, timestamps with the 2 second difference could be a problem in syncing two databases. So the proposal is, to convert all timestamps to timestamps with even seconds. Every timestamp conversion then needs to be filtered thru the 2 seconds correction routine.
| Timestamp A: | 2009-10-03 10:28:02 | -> OK. |
|---|---|---|
| Timestamp B: | 2009-10-03 10:28:01 | -> needs conversion to 2009-10-03 10:28:02 |
Note from KvE:
During my exercises last year, while merging and cleaning the databases from Dirk and Knut, i found that for the old dataset, the inclusion of ftscdate in the dupcheck key resulted in more dupes in the database. If I recall correctly, the differences were larger as the modulo 2 seconds. For the size of the merge, using only folder, msgid and subject pooved to be sufficient.
Athough it will probably not happen anymore, I found that the msgid of messages where this attribute is missing, can reliably be generated before inclusion into the DB. If for purist reasons this atrribute should not be added to the original message, the special attribute will do.
2.11 Dupes Checking
[Apr 2010] Starting with some php coding for *.msg imports into the Fidobase2 I'm running into problems with the dupes checking method as implemented.
Each table has an unique btree index 'dupecheck' folder + ftscdate(18) + msgid + subject
A typical dupecheck query needs to look like:
"select * from fidobase2.echo_".substr($folder,0,1)."
where folder='".$folder."'
and ftscdate like '".substr($ftscdate,0,18)."%'
and msgid='".$msgid."'
and subject='".$subject."';"
Importing a *.msg archive of 18 directories results with approx 20.000 imported messages (!!):
---------- Sat 24 Apr 10, FB2IMP; Import Folder: Import: FIDOCON.BLEICHENBACH.1996
| Archive | Imports | ||
|---|---|---|---|
| Imported | Skipped (Dupes) | Errors | |
| a01 | 602 | 17487 | 0 |
| a02 | 760 | 4320 | 0 |
| a03 | 1447 | 6430 | 0 |
| a04 | 1966 | 7201 | 0 |
| a05 | 830 | 8360 | 0 |
| a06 | 523 | 9046 | 0 |
| a07 | 241 | 9348 | 0 |
| a08 | 27 | 9349 | 0 |
| a09 | 9 | 9832 | 0 |
| a10 | 26 | 9974 | 0 |
| a11 | 0 | 6052 | 0 |
| a12 | 136 | 9364 | 0 |
| a13 | 4561 | 4439 | 0 |
| a14 | 7000 | 0 | 0 |
| BBCON96 | 6227 | 0 | 0 |
| a13a | 70 | 4549 | 0 |
| a13b | 25 | 4353 | 0 |
| a13c | 0 | 12 | 0 |
Archives a01 to a12 are mails from years 2006 upto 2009.
Archive a13 includes mails from the time, Dirks link gots broken so the Fidobase2 database doesn't includes rest of the mails from the archive a13, a14 and BBCON96 (that is the production archive).
a13a, a13b and a13c are archives from a different source converted from CrossPoints Puffer format to FTS1 *.MSG format and imported into the MySQL database Fidobase2.
The question that araises with above statistic was:
- Why so many mails not in the database yet?
- Does the dupecheck not function?
- Are there missing mails in the database?
Missing mails in archives a13, a14 and BBCON96 are expected. But what is with the missing mails from archives a01 to a12 (GT 6300 mails)?
2.11.1 Problem 1: CrossPoint conversion
In analyzing the CrossPoint imports, I've found two problems:
- CrossPoint Dates includes no seconds (forever 00)
- CrossPoint Dates includes TZ info
A typical Puffer transfer Date looks like: "EDA: 20091209184600S+2"
where "20091209" is the date in reverse order: 2009-12-09 => Dec 9th, 2009
and "184600" is the time: 18:46:00 (forever 00 seconds)
and "S+2" is the TZ info difference to the local time. Here: Summertime + 2 hours for local time will result in local time: 20:46:00. Otherwise there is a difference of 2 hours to yet existing mails in the database.
ftscdate like '".substr($ftscdate,0,18)."%' to above query needs a deeper view:
FTSCDATE in the database looks like: 09_Dec_09__20:46:00 (len=19)
For dupechecking the last second part will be stripped: 09_Dec_09__20:46:00
Results in: 09_Dec_09__20:46:0
Rule 1: For CrossPoint imports, the ftscdate dupecheck needs to be modified by removing the seconds part from the dupecheck (addtl. variable DupeCheck CrossPoint Import):
"select * from fidobase2.echo_".substr($folder,0,1)."
where folder='".$folder."'
and ftscdate like '".substr($ftscdate,0,17+($CROSSPOINTIMPORT?0:1))."%'
and msgid='".$msgid."'
and subject='".$subject."';"
UTC notation of dates and times is:
2009-12-09 18:46:00 UTC (UTC time)
2009-12-09 20:46:00 UTC+0200 (local time with UTC difference)
results in 18:46 UTC time or 20:46 local time (under CEST)
CrossPoints notation varies: 2009-12-09 18:46:00 S+2
means, you have to add the Summertime difference of 2 hours
to the existing time: 18:46:00 + 2 hours => 20:46:00
Alternate is W+0, that means add +0 hours, means use the time as is.
2.11.2 Problem 2: Other dupecheck differences against existing database
In the first import tries, the script reported errors and differences. The main problems was:
- "Re:" handling
- Escaping characters before storing to MySQL \'
Some of the subject lines includes "Re:"'s. So therefor the dupecheck doesn't found the records that were saved before w/o the "Re:"'s.
Add removal of "Re:"'s before importing
Error messages appears that some records couldn't be saved. By analyzing the text, subject lines, message text lines and Origin lines includes a special character ' (39d, 27h)
To import this char, the string needs to be escaped before importing => \'
Add escaping of ' before importing
The next try of import results in better identifying dupes, but there are much more problems.
A deeper analyze of the dupechecking results in the following log:
# 04:12:18 Import: path F:/ECHOBASE/BBCON96/a01/ # 04:14:20 Mail content mismatch MsgId found: 78.msg # 04:14:20 - FTSCDATE expected: 28 May 06 23:08:16 # 04:14:20 - FTSCDATE found : 28 May 06 23:08:17 # 04:14:20 - SUBJECT RE difference in db: Re: nach der Con ist vor der Con # 04:16:44 Mail content mismatch MsgId found: 7464.msg # 04:16:44 - SUBJECT expected: nummern # 04:16:44 - SUBJECT found : Re^2: nummern # 04:16:46 Mail content mismatch MsgId found: 7532.msg # 04:16:46 - SUBJECT expected: nummern # 04:16:46 - SUBJECT found : Re^4: nummern # 04:16:46 dupe found: 7532.msg (MsgID) # 04:16:46 Mail content mismatch MsgId found: 7538.msg # 04:16:46 - SUBJECT RE difference in db: Re: Re^4: nummern # 04:16:46 dupe found: 7538.msg (MsgID) # 04:23:12 FTSCDATE differences: 1 # 04:23:12 SUBJECT differences: 2 # 04:23:12 SUBJECT 'RE:' differences: 557 # 04:23:12 SUBJECT 'RE:' differences source MSG: 0 # 04:23:12 SUBJECT 'RE:' differences source DB : 557 # 04:23:12 Messages imported: 0, skipped: 18089, error: 0 --------------------------------- # 04:23:13 Import: path F:/ECHOBASE/BBCON96/a02/ # 04:27:27 SUBJECT 'RE:' differences: 760 # 04:27:27 SUBJECT 'RE:' differences source MSG: 0 # 04:27:27 SUBJECT 'RE:' differences source DB : 760 # 04:27:27 Messages imported: 0, skipped: 5080, error: 0 --------------------------------- # 04:27:28 Import: path F:/ECHOBASE/BBCON96/a03/ # 04:34:05 Mail content mismatch MsgId found: 7805.msg # 04:34:05 - SUBJECT expected: 51ø13\'35,57" N 6ø46\'19,38" O # 04:34:05 - SUBJECT found : 51°13'35,57" N 6°46'19,38" O # 04:34:06 SUBJECT differences: 1 # 04:34:06 SUBJECT 'RE:' differences: 1445 # 04:34:06 SUBJECT 'RE:' differences source MSG: 0 # 04:34:06 SUBJECT 'RE:' differences source DB : 1445 # 04:34:06 Messages imported: 0, skipped: 7877, error: 0 # 04:34:06 FB2IMP finished. --------------------------------- # 04:34:07 Import: path F:/ECHOBASE/BBCON96/a04/ # 04:42:55 SUBJECT 'RE:' differences: 1966 # 04:42:55 SUBJECT 'RE:' differences source MSG: 0 # 04:42:55 SUBJECT 'RE:' differences source DB : 1966 # 04:42:55 Messages imported: 0, skipped: 9167, error: 0 --------------------------------- # 04:42:55 Import: path F:/ECHOBASE/BBCON96/a05/ # 04:51:14 SUBJECT 'RE:' differences: 829 # 04:51:14 SUBJECT 'RE:' differences source MSG: 0 # 04:51:14 SUBJECT 'RE:' differences source DB : 829 # 04:51:14 Messages imported: 0, skipped: 9190, error: 0 --------------------------------- # 04:51:15 Import: path F:/ECHOBASE/BBCON96/a06/ # 04:55:59 Mail content mismatch MsgId found: 3923.msg # 04:55:59 - SUBJECT expected: auf persťnlichen Wunsch: die 240000er Statistik # 04:55:59 - SUBJECT found : auf persoenlichen Wunsch: die 240000er Statistik # 04:55:59 dupe found: 3923.msg (MsgID) # 04:59:17 SUBJECT differences: 1 # 04:59:17 SUBJECT 'RE:' differences: 522 # 04:59:17 SUBJECT 'RE:' differences source MSG: 0 # 04:59:17 SUBJECT 'RE:' differences source DB : 522 # 04:59:17 Messages imported: 0, skipped: 9569, error: 0 --------------------------------- # 04:59:17 Import: path F:/ECHOBASE/BBCON96/a07/ # 05:00:54 Mail content mismatch MsgId found: 314.msg # 05:00:54 - SUBJECT expected: extra f [129d / 81h] r Tina # 05:00:54 - SUBJECT found : extra fuer Tina # 05:00:54 dupe found: 314.msg (MsgID) # 05:06:52 SUBJECT differences: 2 # 05:06:52 SUBJECT 'RE:' differences: 239 # 05:06:52 SUBJECT 'RE:' differences source MSG: 0 # 05:06:52 SUBJECT 'RE:' differences source DB : 239 # 05:06:52 Messages imported: 0, skipped: 9590, error: 0 --------------------------------- # 05:06:54 Import: path F:/ECHOBASE/BBCON96/a08/ # 05:12:59 SUBJECT 'RE:' differences: 27 # 05:12:59 SUBJECT 'RE:' differences source MSG: 0 # 05:12:59 SUBJECT 'RE:' differences source DB : 27 # 05:12:59 Messages imported: 0, skipped: 8513, error: 0 --------------------------------- # 05:13:00 Import: path F:/ECHOBASE/BBCON96/a09/ # 05:20:04 SUBJECT 'RE:' differences: 9 # 05:20:04 SUBJECT 'RE:' differences source MSG: 0 # 05:20:04 SUBJECT 'RE:' differences source DB : 9 # 05:20:04 Messages imported: 0, skipped: 9841, error: 0 --------------------------------- # 05:20:05 Import: path F:/ECHOBASE/BBCON96/a10/ # 05:29:00 SUBJECT 'RE:' differences: 26 # 05:29:00 SUBJECT 'RE:' differences source MSG: 0 # 05:29:00 SUBJECT 'RE:' differences source DB : 26 # 05:29:00 Messages imported: 0, skipped: 10000, error: 0 --------------------------------- # 05:29:01 Import: path F:/ECHOBASE/BBCON96/a11/ # 05:33:38 Messages imported: 0, skipped: 6052, error: 0 --------------------------------- # 05:33:39 Import: path F:/ECHOBASE/BBCON96/a12/ # 05:41:01 SUBJECT 'RE:' differences: 113 # 05:41:01 SUBJECT 'RE:' differences source MSG: 0 # 05:41:01 SUBJECT 'RE:' differences source DB : 113 # 05:41:01 Messages imported: 0, skipped: 9500, error: 0 --------------------------------- # 05:41:01 Import: path F:/ECHOBASE/BBCON96/a13/ # 05:48:19 SUBJECT 'RE:' differences: 12 # 05:48:19 SUBJECT 'RE:' differences source MSG: 0 # 05:48:19 SUBJECT 'RE:' differences source DB : 12 # 05:48:19 Messages imported: 0, skipped: 9000, error: 0 --------------------------------- # 05:48:20 Import: path F:/ECHOBASE/BBCON96/a14/ # 05:54:05 Messages imported: 0, skipped: 7000, error: 0 --------------------------------- # 05:54:06 Import: path F:/ECHOBASE/BBCON96/ # 05:56:38 dupe found: 6263.MSG (-RE) # 05:56:38 dupe found: 6264.MSG (-RE) # 05:56:38 dupe found: 6265.MSG (-RE) # 05:56:39 dupe found: 6266.MSG (-RE) # 05:56:39 Messages imported: 0, skipped: 6285, error: 0 --------------------------------- # 05:56:40 Import: path F:/ECHOBASE/BBCON96/a13/a13a/ problems on import based on a bug of the CrossPoint to FTS1 msg converter --------------------------------- # 05:59:57 Import: path F:/ECHOBASE/BBCON96/a13/a13b/ problems on import based on a bug of the CrossPoint to FTS1 msg converter --------------------------------- # 06:02:39 Import: path F:/ECHOBASE/BBCON96/a13/a13c/ problems on import based on a bug of the CrossPoint to FTS1 msg converter ---------------------------------
This log displays several more problems in identifying dupes:
2.11.2.1 Re: problems
- stripping "Re:"'s hasn't been made on all records. Some entrys are stripped, some entrys includes "Re:"'s (maybe older records)
- yet existing "Re:" problems are differences that are allready in the database
- its not only a "Re:" problem, also "Re^2:" and "Re^4:" variations
2.11.2.2 Subject problems
- \' escaping problems (before? after? checking?)
- Umlaut differences ” vs. oe, char 129d / 81h vs. ue
2.11.2.3 ftscdate differences4
- there still exists one one-second difference: expected: 23:08:16, found: 23:08:17
- there are many 1 hour differences dupes (probably results of a faulty timezone conversion)
# 14:17:44 searching # 14:17:44 msgid : 28.juno@1:14/400 0926ac03 # 14:17:44 folder : JUNO # 14:17:44 ftscdate: 21 Jul 06 17:36:00 # 14:17:44 subject : AIM # 14:17:44 probably dupe found: db2, weight: (2009) # 14:17:44 rec(1) id : 172 # 14:17:44 msgid : 28.juno@1:14/400 0926ac03 # 14:17:44 folder : JUNO # 14:17:44 ftscdate: 21 Jul 06 16:36:00 # 14:17:44 subject : AIM # 14:17:44 weight : (2009) # 14:17:44 dupe found: 547 (extended)
2.11.2.4 MsgID dupes
- imports from archives a13a, a13b and a13c (CrossPoint imports) consists of many MsgID dupes not yet realy identified2 solved
- database should include records with missing MsgID's
Solution by Kees:
If there is no MsgID available1, create a msgid based on:
CRC32 of text part, w/o Kludges until the Origin line. and pre NOMSGID text for identifying those specials
Perl script:
# Extract MSGID ------------------------------------------------------
$y = index($kludges, "MSGID:");
if ( $y < 0 ) {
$crc32 = (crc32($body,0xffffffff) ^ 0xffffffff);
$msgid = sprintf("NOMSGID %s %08x",$originnode,$crc32);
}
else {
$msgid = substr($kludges, $y + 7);
$y = index($msgid, "\x01");
if ( $y >= 0) {
$msgid = substr($msgid, 0, $y );
}
}
-------------------------------------------------------------------
1 probably only mails before 2006
2 The MsgID dupes prob relates to a bug in the CrossPoint to FTS1 *.MSG converter, that stripped half of the informations of MsgIDs. Needs to be reviewed in next import try.
2.11.3 Introducing weights in analyzing dupe problems
I've added a dupe weight system in analyzing dupe problems.
ftscdate differences => +/- 9 points
or
ftscdate +/- 1 or +/- 2 hour(s) difference => 1000 points
subject variations in percent * 10, max 100 (*10 = 1000 points)
folder identical = + 1000 points
body content identical = + 10000 points
2.11.4 Problem cases with missing MsgId
# 18:40:50 missing msgid db1 rec id (4118) # 18:40:50 folder : JOKES.GER # 18:40:50 ftscdate: 23 Jan 03 20:07:00 # 18:40:50 msgid : # 18:40:50 subject : 2 einer noch :-) # 18:40:50 originnode: 2:240/2188.37 # 18:40:50 origin: <.^.> (2:240/2188.37) # 18:40:50 fromaka: 2:240/5138 # 18:40:50 new msgid: 1:2320/105.999 40f6575e
MsgUd hasn't been created from orgin AKA. It uses the Kludges content which includes a MsgId: "1:2320/105.999 40f6575e"
Kludges field of Message:
[ctrl+A]RESCANNED 2:240/5138
[ctrl+A]SPLIT: 23 Jan 03 22:22:24 @240/2188 5 02/02 +++++++++++
[ctrl+A]PID: XP 3.12d R/A17545
[ctrl+A]CHRS: IBMPC 2
[ctrl+A]PATH: 240/2188 2468/9929 9911 24/903 2432/200 240/5778 5138
[ctrl+A]PID: MBSE-FIDO 0.36.00
[ctrl+A]CHRS: IBMPC 2
[ctrl+A]ACUPDATE: DELETE comcast.com 7b9f2196
[ctrl+A]TID: MBSE-FIDO 0.36.00
[ctrl+A]RFC-From: Cosmo Roadkill <...>
[ctrl+A]RFC-Control: cancel <...>
[ctrl+A]RFC-Organization: BOFH Space Command, Usenet Division
[ctrl+A]RFC-Message-ID: <...>
[ctrl+A]RFC-Sender: <...>(KenFuny)
[ctrl+A]RFC-Approved: ...
[ctrl+A]RFC-X-No-Archive: yes
[ctrl+A]RFC-X-Cancelled-By: ...
[ctrl+A]RFC-X-Original-Path: ....POST
[ctrl+A]RFC-X-Original-Subject: Satan's Lawyer
[ctrl+A]RFC-X-Original-Date: Tue, 21 Jan 2003 13:59:34 -0600
[ctrl+A]RFC-X-Original-NNTP-Posting-Host: 68.62.134.31
[ctrl+A]RFC-X-Original-From: <...>(KenFuny)
[ctrl+A]RFC-X-Original-X-Trace: ...
[ctrl+A]RFC-X-CosmoTraq: ...
[ctrl+A]RFC-X-Cancel-ID: ...
[ctrl+A]RFC-X-Commentary: Spam is lame. Spammers are bad.
[ctrl+A]PATH: 248/4001 24/903 2432/200 240/5778 5138
[ctrl+A]RFC-Content-Transfer-Encoding: 8bit
[ctrl+A]GATEWAY: RFC1036/822 fifi.woody.ch [FIDOGATE 4.4.9]
[ctrl+A]SPLIT: 24 Feb 05 14:05:24 @301/812 2254 04/04 +++++++++++
[ctrl+A]PATH: 301/812 808 2432/200 240/5778 5138
[ctrl+A]GATEWAY: RFC1036/822 mordor.mailstation.de [FIDOGATE 4.4.4]
[ctrl+A]PATH: 2437/209 40 2432/200 240/5778 5138
[ctrl+A]PATH: 2471/77 2476/480 24/903 2432/200 240/5778 5138
[ctrl+A]RFC-Content-Transfer-Encoding: 8bit
[ctrl+A]GATEWAY: RFC1036/822 fidogate.albi.life.de [FIDOGATE 4.4.9],
FIDO fidogate.albi.life.de [FIDOGATE 4.4.9]
[ctrl+A]PATH: 2471/77 2476/480 24/903 2432/200 240/5778 5138
[ctrl+A]PATH: 301/812 808 2432/200 240/5778 5138
[ctrl+A]Content-Transfer-Encoding: quoted-printable
[ctrl+A]X-MIME-Autoconverted: from 8bit to quoted-printable by delorie.com id i6F02I46007522
[ctrl+A]X-Foreign-Sender: 207.22.48.162
[ctrl+A]X-UIDL: b9ff87542029c292827ac1ac3436e77d
------------------------------------------------------------------------------
[ctrl+A]MSGID: 1:2320/105.999 40f6575e
[ctrl+A]REPLY: <...> 82a5ddd2
[ctrl+A]PATH: 2320/105 261/38 123/500 774/605 2432/200 240/5778 5138
[ctrl+A]X-MIME-Autoconverted: from quoted-printable to 8bit by delorie.com id i6EBv3Hu021947
[ctrl+A]Reply-To: ...
[ctrl+A]Errors-To: ...
[ctrl+A]X-Mailing-List: ...
[ctrl+A]X-Unsubscribes-To: ...
[ctrl+A]Precedence: bulk
[ctrl+A]Content-Transfer-Encoding: quoted-printable
[ctrl+A]X-MIME-Autoconverted: from 8bit to quoted-printable by delorie.com id i6EBv4P5021952
[ctrl+A]X-Foreign-Sender: 207.22.48.162
[ctrl+A]X-UIDL: 9bde4c0bf78e2965e01186b4d0317109
[ctrl+A]MSGID: 1:2320/105.999 40f59f5e
[ctrl+A]PATH: 2320/105 261/38 123/500 774/605 2432/200 240/5778 5138
[ctrl+A]X-Foreign-Sender: 207.22.48.162
[ctrl+A]X-Spam-Checker-Version: SpamAssassin 2.63 (2004-01-11)
[ctrl+A]X-Spam-Status: No, hits=-2.9 required=4.0 tests=BAYES_00,MSGID_FROM_MTA_HEADER
[ctrl+A]X-Spam-Level:
[ctrl+A]X-UIDL: 44e29c162ed0d8a42e026ff2e6346ce2
[ctrl+A]MSGID: 1:2320/105.999 4052ef89
[ctrl+A]PATH: 2320/105 261/38 123/500 774/605 2432/200 240/5778 5138
[ctrl+A]REPLYALSO ...
[ctrl+A]MSGID: 1:2320/105.999 3fd5acc7
[ctrl+A]PATH: 2320/105 261/38 123/500 774/605 2432/200 240/5778 5138
[ctrl+A]REPLYADDR ...
[ctrl+A]REPLYALSO ...
[ctrl+A]PATH: 2320/105 261/38 123/500 774/605 2432/200 240/5778 5138
The problem with this mail is to identify where this mail comes from, sent by
# 18:40:50 originnode: 2:240/2188.37
The first header line gives an idea, that this mail comes from a rescan
[ctrl+A]RESCANNED 2:240/5138
with a path thru
[ctrl+A]PATH: 240/2188 2468/9929 9911 24/903 2432/200 240/5778 5138
before rescan
that was originaly an import of a nntp post ???
The problem that persists is the multiple paths:
1. [ctrl+A]PATH: 240/2188 2468/9929 9911 24/903 2432/200 240/5778 5138
2. [ctrl+A]PATH: 248/4001 24/903 2432/200 240/5778 5138
3. [ctrl+A]PATH: 301/812 808 2432/200 240/5778 5138
4. [ctrl+A]PATH: 2437/209 40 2432/200 240/5778 5138
[ctrl+A]PATH: 2471/77 2476/480 24/903 2432/200 240/5778 5138
5. [ctrl+A]PATH: 2471/77 2476/480 24/903 2432/200 240/5778 5138
[ctrl+A]PATH: 301/812 808 2432/200 240/5778 5138
6. [ctrl+A]PATH: 2320/105 261/38 123/500 774/605 2432/200 240/5778 5138
7. [ctrl+A]PATH: 2320/105 261/38 123/500 774/605 2432/200 240/5778 5138
8. [ctrl+A]PATH: 2320/105 261/38 123/500 774/605 2432/200 240/5778 5138
9. [ctrl+A]PATH: 2320/105 261/38 123/500 774/605 2432/200 240/5778 5138
10.[ctrl+A]PATH: 2320/105 261/38 123/500 774/605 2432/200 240/5778 5138
All paths goes thru "2432/200 240/5778 5138"
But what its a mistery with this mail, the different delivery paths before that. How can one mail be delivered thru different channels resulting in one mail ?!?
As source the paths listed under 6. to 10. seems to be the origin
- [ctrl+A]MSGID: 1:2320/105.999 40f6575e
- [ctrl+A]REPLY: <...> 82a5ddd2
- [ctrl+A]PATH: 2320/105 261/38 123/500 774/605 2432/200 240/5778 5138
In block 3 of above listed header information
[ctrl+A]RFC-X-Original-Subject: Satan's Lawyer
[ctrl+A]RFC-X-Original-Date: Tue, 21 Jan 2003 13:59:34 -0600
the original subject and date can be set as the first entry point.
A forward in the FTN Echo JOKES.GER with an ftscdate: 23 Jan 03 20:07:00
has been modified with the subject 2 einer noch :-) by originnode: 2:240/2188.37
If the source of the FTN mail is from originnode 2:240/2188.37, the proposed NOMSGID routine
...
$y = index($kludges, "MSGID:");
if ( $y < 0 ) {
$crc32 = (crc32($body,0xffffffff) ^ 0xffffffff);
$msgid = sprintf("NOMSGID %s %08x",$originnode,$crc32);
}
else {
$msgid = substr($kludges, $y + 7);
...
needs to be modified that way, that aka from originnode becomes the higher priority. This will reflect the analyze results from this mail example.
modified routine
# Extract MSGID ------------------------------------------------------
if ($originnode != "" ) {
$crc32 = (crc32($body,0xffffffff) ^ 0xffffffff);
$msgid = sprintf("NOMSGID %s %08x",$originnode,$crc32);
} else {
$y = index($kludges, "MSGID:");
if ( $y < 0 ) {
$crc32 = (crc32($body,0xffffffff) ^ 0xffffffff);
$msgid = sprintf("NOMSGID %s %08x",$originnode,$crc32);
}
else {
$msgid = substr($kludges, $y + 7);
$y = index($msgid, "\x01");
if ( $y >= 0) {
$msgid = substr($msgid, 0, $y );
}
}
}
-------------------------------------------------------------------
2.11.5 Many dupes w/o identical body content and probably tearline differences
# 18:40:19 searching # 18:40:19 msgid : 2:240/2188.23@fidonet 2f31b525 # 18:40:19 folder : JOKES.GER # 18:40:19 ftscdate: 07 Apr 05 12:21:00 # 18:40:19 subject : Anwaelte I. # 18:40:19 dupe found: 143, weight: (2004) # 18:40:19 rec(1) id : 142 # 18:40:19 msgid : 2:240/2188.23@fidonet 2f31b525 # 18:40:19 folder : JOKES.GER # 18:40:19 ftscdate: 05 Jun 06 22:00:42 # 18:40:19 subject : Anwaelte I. # 18:40:19 weight : (2004) # 18:40:19 dupe found, skipped. db1 id: 143 (extended)
Needs further analyze...
same length, but different crc32 (???)
# 03:25:13 rec(543) id : 162 # 03:25:13 len body 1 / crc: 574, ADFB033E # 03:25:13 len body 2 / crc: 574, 237404DD # 03:25:13 searching # 03:25:13 msgid : 20.juno@1:14/400 092312c8 # 03:25:13 folder : JUNO # 03:25:13 ftscdate: 19 Jul 06 00:17:00 # 03:25:13 subject : Juno # 03:25:13 dupe found: 543, weight: (3000) # 03:25:13 rec(1) id : 162 # 03:25:13 msgid : 20.juno@1:14/400 092312c8 # 03:25:13 folder : JUNO # 03:25:13 ftscdate: 18 Jul 06 23:17:00 # 03:25:13 subject : Juno # 03:25:13 weight : (3000) # 03:25:13 dupe found, skipped. db1 id: 543 (extended)
On a 2nd run with more debugging infos ...
# 03:40:01 rec(543) id : 162 # 03:40:01 len body 1 / crc: 574, ADFB033E # 03:40:01 len body 2 / crc: 574, 237404DD # 03:40:01 difference(s): # 03:40:01 body 1: 12-Win32 # 03:40:01 body 2: 11-Win32
The "12-Win32" and "11-Win32" info is part of the TID kludge ...
so probably a problem with the stripkludge() function exists ?!?
btw. most differences starts with "12-Win32" and "11-Win32" ...
TID: SBBSecho 2.11-Win32 r1.170 Sep 11 2005 MSC 1200
vs.
TID: SBBSecho 2.12-Win32 r1.183 Jan 7 2007 MSC 1200
comparing the ftscdates ...
# 03:40:01 ftscdate: 19 Jul 06 00:17:00 # 03:40:01 ftscdate: 18 Jul 06 23:17:00
it becomes courious ... how a mail could be modified with a software with a TID where the software was compiled half a year later ?!?
Was this mail a result of a software upgrade ? and has this mail been resent after the software upgrade ?!?
From a review, the 2nd mail is a dupe, that needs to be eliminated.
The problem: how can this be done?
The body part has been stored with parts of the kludge lines.
Those kludge lines needs to be stripped before analyzing the body content.
So this has been done in the program. But this procedure probably doesn't work as expected.
From the structure of the stored body:
AREA:areaname + 0D 01 + Kludge 1 + 0D 01 + Kludge 2 + 0D 01 + Kludge 3 + 0D text
the Area and the kludges lines needs to be stripped.
The stripkludge() routine searches for chr(1) positions and continues searching for further chr(1) positions until no more chr(1) is found. The last step is to search the next occurance of chr(13) and storing the string that follows this position.
On a test program, the exported body text i've saved to a text file and run the stripkludges() routine over the exported text files.
The difference wasn't the kludge lines - it is a difference in the tearline (!!)
--- SBBSecho 2.11-Win32 --- SBBSecho 2.12-Win32
The result of this test is: the stripkludges() procedure works.
The tearline difference needs further rethinking.
The result is, to modify the stripkludges() routine to strip the kludges within the body and also strip all following the tearline.
The interesting thing is, that now all body differences are now fixed...
except one difference in lenght:
# 04:54:50 rec(143) id : 142 # 04:54:50 len body 1 / crc: 1229, 1B3BE546 # 04:54:50 len body 2 / crc: 1204, 22F15FC6 # 04:54:50 searching # 04:54:50 msgid : 2:240/2188.23@fidonet 2f31b525 # 04:54:50 folder : JOKES.GER # 04:54:50 ftscdate: 07 Apr 05 12:21:00 # 04:54:50 subject : Anwaelte I. # 04:54:50 dupe found: 143, weight: (2004) # 04:54:50 rec(1) id : 142 # 04:54:50 msgid : 2:240/2188.23@fidonet 2f31b525 # 04:54:50 folder : JOKES.GER # 04:54:50 ftscdate: 05 Jun 06 22:00:42 # 04:54:50 subject : Anwaelte I. # 04:54:50 weight : (2004) # 04:54:50 dupe found, skipped. db1 id: 143 (extended)
The difference(s) are hard carriage returns in the first entry.
Line endings in mail with ftscdate 05 Jun 06 22:00:42 are 0Dh only.
Line endings in the mail with ftscdate 07 Apr 05 12:21:00 are 0Dh + 0Ah
25 line endings with addtl. 0Ah results in above length difference.
So body content needs also "normalized" by replacing line terminations 0Dh + 0Ah to 0Dh only.
From another table, echo_2 the results displays some
# 05:53:43 searching # 05:53:43 msgid : 2:2437/22 1ae791a1 # 05:53:43 folder : 2437.NETZ # 05:53:43 ftscdate: 22 Sep 08 02:35:13 # 05:53:43 subject : Urlaub # 05:53:43 differences found: 2520 # 05:53:43 rec(1) id : 2425 # 05:53:43 msgid : 2:2437/22 1ae791a1 # 05:53:43 folder : 2437.SMALLTALK # 05:53:43 ftscdate: 22 Sep 08 02:35:13 # 05:53:43 subject : Urlaub # 05:53:43 weight : (0)
This is probably from crosspostings that results in the same MsgID under different echoes. So therefor the folder check is an essential requirement.
2.11.6 New dupecheck proposal
On dupechecking test folder + ftscdate(18) + MsgID + Subject:
-
on ftscdate test:
- ftscdate(17)
-
on subject test:
-
modify variations on import source subject line:
- subject w/ and w/o escaped chars
- subject w/ and w/o stripped Re:'s
- subject w/ and w/o transliterated Umlauts
-
assumtion that the subject line in database contains:
- subject w/ escaped chars where source subject line doesn't include escaped chars (???)
- subject w/ Re:'s where source subject line doesn't include Re:'s. Add Re variations to subject line
- reconvert transliterated subjects in database to Umlauts (???)
-
modify variations on import source subject line:
-
if all tests fails:
- test against MsgID only
Also prevent modifications of subject line before trying to save it into the database. Probably on dupechecking, the transformed (escaped chars, Umlauts) subject lines results in not found.
i.e.
# 04:34:05 - SUBJECT expected: 51ø13\'35,57" N 6ø46\'19,38" O # 04:34:05 - SUBJECT found : 51°13'35,57" N 6°46'19,38" O
Subject expected was escaped before dupechecking. Maybe its better to use the raw subject line on dupechecking and thereafter make all the transformations for saving into the database.
2.11.6.1 Alternate procedure:
- Search for MsgID only1
- Read all found records
Compare all records against addtl. search pattern (ftscdate2, subject)
1 MsgID is not an default index yet. Needs to be added to the database structure.
2 ftscdate +/- 1 Std. or +/- 2 Std.
Default Index on tables:
| Primary | ID |
|---|---|
| dupecheck | folder+ftscdate(18)+msgid+subject |
| Export | datetime+folder |
| Statistics | datewritten |
| to add: imsgid (not yet defined) | msgid |
2.11.7 New rules importing messages proposal
As long as the subject field is part of the index, the subject line needs to be "normalized" before importing despite the fact that existing records in database includes such specials to prevent further problems1:
- strip Re:'s before importing
- escape strings before importing
- transliterate Umlauts (ö -> oe, ť -> oe) (on subject lines)
- replace 0Dh + 0Ah line terminations with 0Dh line terminations in body content
1 a full reorganisation (normalize) of the database content is the prefered option
Required Normalize actions on table fields:
| Field | intval | addslashes | umlaut | strip x0A | strip RE's | CheckFieldLength |
|---|---|---|---|---|---|---|
| id | + | - | - | - | - | - |
| ftscdate | - | - | - | - | - | + (19) |
| datetime | - | - | - | - | - | - |
| folder | - | - | - | - | - | - |
| fromnode | - | - | - | - | - | - |
| tonode | - | - | - | - | - | - |
| fromname | - | + | - | - | - | - |
| toname | - | + | - | - | - | - |
| subject | - | + | + | - | + | + (72) |
| attrib | + | - | - | - | - | - |
| msgid | - | - | - | - | - | - |
| replyid | - | - | - | - | - | - |
| origin | - | + | - | - | - | - |
| path | - | - | - | - | - | - |
| local | - | - | - | - | - | - |
| rcvd | - | - | - | - | - | - |
| sent | - | - | - | - | - | - |
| kludges | - | + | - | - | - | - |
| body | - | + | - | + | - | - |
| seenby | - | - | - | - | - | - |
| datewritten | - | - | - | - | - | - |
| Uplink | + | - | - | - | - | - |
2.11.8 Modified Fidobase2 Structure
Structure for all tables
DROP TABLE IF EXISTS `echo_0`;
SET @saved_cs_client = @@character_set_client;
SET character_set_client = utf8;
CREATE TABLE `echo_0` (
`id` int(11) NOT NULL auto_increment,
`ftscdate` varchar(20) NOT NULL default '',
`datetime` timestamp NOT NULL default CURRENT_TIMESTAMP on update CURRENT_TIMESTAMP,
`folder` varchar(72) NOT NULL default '',
`fromnode` varchar(72) NOT NULL default '',
`tonode` varchar(72) NOT NULL default '',
`fromname` varchar(36) NOT NULL default '',
`toname` varchar(36) NOT NULL default '',
`subject` varchar(72) NOT NULL default '',
`attrib` smallint(5) unsigned NOT NULL default '0',
`msgid` varchar(72) NOT NULL default '',
`replyid` varchar(72) NOT NULL default '',
`origin` varchar(72) NOT NULL default '',
`path` varchar(255) NOT NULL default '',
`local` char(1) NOT NULL default 'Y',
`rcvd` char(1) NOT NULL default 'N',
`sent` char(1) NOT NULL default 'N',
`kludges` mediumblob,
`body` mediumblob,
`seenby` mediumblob,
`datewritten` datetime default NULL,
`Uplink` int(10) unsigned default '0',
PRIMARY KEY (`id`),
UNIQUE KEY `dupecheck` USING BTREE (`folder`,`ftscdate`(18),`msgid`,`subject`),
KEY `Export` (`datetime`,`folder`),
KEY `Statistics` (`datewritten`),
KEY `imsgid` USING BTREE (`msgid`)
) ENGINE=MyISAM DEFAULT CHARSET=latin1;
SET character_set_client = @saved_cs_client;
2.11.9 Practicle problems normalizing existing database
Reading each table, normalize content, check against dupes on new database 2 and saving the normalized records to Fidobase2 script terminates with Out of memory
With 2 Gb used memory by selecting all records from table echo_f needs some further modifications to the script.
limit results to 1000 records?
continue selecting id GT last analyzed record?
in a main loop ...
... results in a continuous memory usage of approx 10.900.000 bytes, sometimes below 10 Mb
Debug log displays:
# 03:39:11 dupe found: 3002, weight: (12009)
that means, the script runs the 3rd main loop iteration w/o memory overflows.
Problem solved.
I've reduced the debugging infos to get only essential infos about mismatches is also a problem in identifying script problems:
# 03:45:47 dupe found: 7167, weight: (12009) # 03:45:47 dupe found: 7168, weight: (12009) # 03:45:48 dupe found: 7169, weight: (12009) # 03:45:48 dupe found: 7171, weight: (12009)
In manualy inspecting those debugging infos, first I have to query fidobase1 for id='7167', getting the msgid, and searching this msgid in fidobase2.
The re-check is to search for the given msgid in fidobase1, that results also with one record.
MySQL admin lists 196.042 records in table echo_f, so probably this record was stored in a previous run.
So here, I stopped analyzing the dupechecking algorythm, and reset the fidobase2 for a full import run.
[07.05.2010 04:30] Script started [07.05.2010 13:45] Script finished
2.11.9.1 Problem cases:
Case 1:
Fileliste der letzten 7 Tage vom 15.02.07
001/014: Allgemeines / Files aus dem Fido-Netz
------------------------------------------------------------------------------
1: FNEWSO06.ZIP 10.02.07 7K FIDONEWS 05 Feb 2007 Vol 24 No 06
FIDONEWS 05 Feb 2007 Vol 24 No 06
...
2: NODEDIFF.A40 10.02.07 4K Fidonet NODEDIFF for this week (ARC)
vs.
Fileliste der letzten 7 Tage vom 15.02.09
001/014: Allgemeines / Files aus dem Fido-Netz
------------------------------------------------------------------------------
1: FNEWSQ06.ZIP 14.02.09 7K FIDONEWS 09 Feb 2009 Vol 26 No 06
FIDONEWS 09 Feb 2009 Vol 26 No 06
...
2: NODEDIFF.A44 14.02.09 4K Fidonet NODEDIFF for this week (ARC)
MsgID in both cases: 2:2490/5000 eb512051
Same folder, Same length, different ftscdate, different body CRC.
13 chars different in body text.
Debug info from log:
# 04:47:45 rec(98915) id : 15836 # 04:47:45 len body 1 / crc: 2421, A5712533 # 04:47:45 len body 2 / crc: 2421, 27D94809 # 04:47:45 difference(s): # 04:47:45 body 1: 09 001/014: Allgemeines / Files aus dem # 04:47:45 body 2: 07 001/014: Allgemeines / Files aus dem # 04:47:45 dupe found: 98915, weight: (2009)
On visual review I say, this is No dupe.
Analyze of last run seems to be impossible after 4 weeks of inactivity ... so another try of full reorg needs to be started:
2.11.10 Full database reorg routine (try #2)
- get origin AKA. On missing Origin continue with reorg
- on empty MsgId, build MsgId on the fly
- normalize subject (remove Re's, umlaut transliteration, max length cut)
-
dupefind routine
- test all raw index data (folder, ftscdate, msgid, subj) - skip if dupe found
- otherwise:
search msgid only - check identical folder
- check subj w/o and w/ normalize
- check ftscdate variations (i.e. 1 or 2 hours differences, seconds differences)
- body (w/o kludges) crc check w/o and w/ normalize (strip 0Dh+0Ah, umlaut transliteration)
- otherwise:
on identical string length, write debug log - dupes needs to be over 10.000 pts level (body identical)
- report save message errors w/ details
2.11.11 Problem Cases
(logfile see: zsh1amb4:driveI:/Apache/Apache2/fbmaint/Kopie von FB2IMP2_debug.log)
2.11.11.1 Problem Case 1:
| SeenBy Field content | Let's not underestimate the forceSEEN-BY: 5/0 7102/1 7105/1 7106/20 22 |
|---|---|
| Results in | # 13:00:55 ERROR: SQL error: (1064) You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 's not underestimate the forceSEEN-BY: 5/0 7102/1 7105/1 7106/20 |
| Solution |
check and verify SeenBy field Seenby field have to start with: "SEEN-BY: ..." |
| Same with... | |
# 13:00:55 E insert message failed: 118944 - echo_W:
# 13:00:54 E insert message failed: 118869 - echo_W: they'SEEN-BY:
|
|
2.11.11.2 Problem Case 2:
| Many Dupes found | * |
|---|---|
| Analyze |
body crc identical ftscdate and path varies path differences: id "4438": 396/45 106/1 123/500 774/605 2432/200 id "28616": 396/45 261/38 140/1 772/1 2432/200 |
| Solution |
needs discussion eliminate dupes based on identical body crc? keep dupes caused by different ftscdate? A resend after about 15 months later, or late distribution thru 2nd path... |
| Same with... | |
# 12:35:43 * dupe found: (VATICAN) 28617, weight: (12000)
# 12:35:43 * dupe found: (VATICAN) 28618, weight: (12000)
# 12:35:43 * dupe found: (VATICAN) 28619, weight: (12000)
# 12:35:43 * dupe found: (VATICAN) 28620, weight: (12000)
# 12:35:43 * dupe found: (VATICAN) 28621, weight: (12000)
# 12:35:43 * dupe found: (VATICAN) 28622, weight: (12000)
# 12:35:43 * dupe found: (VATICAN) 28623, weight: (12000)
# 12:35:43 * dupe found: (VATICAN) 28624, weight: (12000)
# 12:35:43 * dupe found: (VATICAN) 28625, weight: (12000)
and many more...
|
|
| Action | needs discussion about dupes check also based on body-crc check |
Chapter 3 - Practicle Starters for Deployment
3.1 Software
3.1.1 PhFiTo
An alternate can be the PhFiTo project at SourceForge.net. A PHP tosser project with multiple ftn api's
This is a part of PhFiTo (aka PHP Fido Tosser) Copyright (c) Alex Kocharin, 2:50/13 This program is distributed under GNU GPL v2 See docs/license for details $Id: phfito.php,v 1.13 2008/03/18 22:31:28 kocharin Exp $
API's included in this package:
- FIPS
- JAM
- MsgBase
- MySQL
- OPUS
- phBB2
- phBB3
- Squish
- XMLbase
- PKT
3.1.2 smapi
SMAPI is part of the Husky project:
Smapi is a modified message API for accesing *.MSG, Squish and Jam message base files.
Husky project at SourceForge.net.
Husky project site
Husky - Basic Files - smapi
3.2 SQL layer in php
PHPnuke core module (db/ structure)
Includes:
- MySQL
- sqlite
- postgres
- mssql
- oracle
- msaccess
- mssql-odbc
- db2
(and possible others to extend)
3.2.1 Database Replication, Synchronisation
Wiki SyncML
SyncML Schema
SyncML PHP project
SyncML Toolkits
Multiversion Concurrency Control (MCC or MVCC)
-
NAMING AND SYNCHRONIZATION IN A DECENTRALIZED COMPUTER SYSTEM by Reed, D.P. (NAMOS)
- LCS Document Number: MIT-LCS-TR-205
- Publication Date: 10-1-1978
3.2.2 Synchronize MySQL Databases with PHP
Synchronize multiple MySQL Databases with PHP
Chapter 4 - Intermediate Summary
The self analyze and the theoretical abstract on synchronisation (NAMOS) leads to following conclusions:
-
A multi-site synchronisation schema can be established.
The maintenance of multi-sites have to be implemented as one addtl. layer
(read subsection 4.1) - Dupe checking is a challenge in the overall process (read subsection 4.2)
- Additional enhancements on records for sync/replication requirements (read subsection 4.3)
4.1 Multi-site synchronisation
The NAMOS sync method has a built-in capability for recovery from unknown errors and unreliable connects. One requirement to implement a sync schema that takes care on unreliable links is therefor achived. The sync method has to allow to add new sites and the removal of sites (node going down one day). This needs to be implemented in the sync process either way as an additional layer with synchronisation (structure upgrade)
4.2 Dupe checking
The dupe checking process has to take care about the following facts:
-
The content of one and the same message may differ from node to node
One has umlauts transliterated, one has RE's removed, one stores messages with DOS line endings, one stores messages with unix line endings - Occasional time differences may occure
So therefor one idea to circumvent dupes is to "normalize" all mails before using mails in the compare process or before importing (normalized dupechecking). The requirements for dupechecking may vary in the future, so the question that arise is how to store the dupechecking information?
- re-compute the dupe identifier every time a message is accessed
- use ftn introduced msgid (there still exist messages w/o msgid's!)
- use of hash value (eg crc) of message body, header or other parameters
- store the "normalized" message together with the raw message into the database
In html email messages, the message consists of header and body, where the body is twofolded, first with the html message and 2nd with the raw txt message. A message record may be split to 1.) header infos, 2.) raw message and 3.) "normalized" message
| smtp header infos |
| smtp body, html message |
| smtp body, txt message |
For ftn message storage this translates to:
| header infos | eg from-node, to-node, ftscdate, kludges | several fields |
|---|---|---|
| raw message | message as received by the node | maybe several fields, eg from, to, subject, header-kludges, body, footer-kludges |
| "normalized" message | transformed message content as used for dupechecking | maybe several fields, eg from, to, subject, header-kludges, body, footer-kludges |
4.3 NAMOS enhancements
The MIT-LCS-TR-205 publication introduces some enhancements to control and assist the sync and replication process.
- Pseudo-time (pt, pt1, pt2, ptN)
- pseudo-times
- pseudo-temporal environments
- Objects
- Object Histories
- Object references (or, or1, or2, orN)
- Version references (vr, vr1, vr2, vrN)
- Possibilities
- Tokens
- Atomic commits
Reference to Multi-site Commit record
| complete threshold |
| abort threshold |
| Timeout |
| list of sites |
Known History Entry
| value |
| start PT |
| end PT |
| commit record |
| commit state |
| previous -> |
Object header, revised to handle creation and deletion
| thread |
| create PT |
| created flag |
| delete PT |
| delete commit record |
| delete state |
FidoBase-Project History Log
| Date | Activities |
|---|---|
| 04.01.2012 |
"Creating the WWB" - NAMOS article found The publication of NAMING AND SYNCHRONIZATION IN A DECENTRALIZED COMPUTER SYSTEM by Reed, D.P. with the NAMOS concept gives some interesting answers to the yet unanswered questions how a synchronize method can be implemented into a multi-site environment |
| 14.12.2011 |
ENET.SYSOP discussion "Creating the WWB" started the discussion brings back the ideas of the fidobase project with some further research on sync methods (MCC, MVCC) |
| 01.06.2010 |
3rd Dupecheck analyze (zsh1amb4:driveI:/Apache/Apache2/fbmaint/Kopie von FB2IMP2_debug.log) |
| 07.05.2010 |
2nd Dupecheck analyze (zsh1amb4:driveI:/Apache/Apache2/fbmaint/fb2imp) |
| 26.04.2010 |
Dupecheck problem analyze Writing my own php import script, I'm running into the dupechecks problem. Many errors, many problems results in a new section: Dupechecking |
| 22.04.2010 |
Link list updated Between Oct and Dec 2009 the link 2443/1313 - 2432/200 gots broken. April 2010 a request received me about missing links. Links have been updated. |
| 20.10.2009 |
Last documentation changes |
| 30.09.2009 |
Starting Documentation As of a long time development w/o any documentation, i'll give this a try. If there is new infos from the past, they will be added. |